One of the biggest challenges with movement tracking is dealing with volatile quality of smartphone location. Numerous factors affect location accuracy such as:
- Quality of GPS receiver
- Source of signal (GPS, WiFi, cell tower triangulation)
- Environment (weather, skyline, visibility, enclosed spaces, multipath reception)
- Device state (low power mode, flight mode, initial fix)
Due to the error introduced by all these factors, it becomes essential to carefully process the location stream in order to accurately infer the path taken by a driver.
At HyperTrack, we have developed half a dozen filters through which a driver’s location stream is processed before our customers consume it through API gets, tracking visuals and events. In this blog, I want to brief you on how we designed our initial filtering pipeline and how we built a validation framework around it.
At a high level, we have two categories of filters. Binary filters (yes/no) to remove noisy location readings and adjustment filters to fine-tune location readings for smoother polylines and accurate mileage calculation. Binary filters look at attributes of the location reading (source speed bearing accuracy timestamp) and apply heuristics around distance, acceleration, clustering, stationary vs moving, etc. to weed out inaccurate readings. Adjustment filters are more algorithmic & resource intensive in nature. While each of those are worthy of a blog post on their own, I will provide a brief overview of our adjustment filters:
-
Kalman Filter: This uses the past location stream to predict the next location coordinate, which is then weighted-averaged (using noise) against actual reading to derive the final coordinates. This is compute intensive and requires past readings to build historical models. We find it effective in correcting errors in noisy data.
-
OSM Filter: This uses publicly available OpenStreetMap road data and maps our GPS traces to nearest possible roads. This is the last filter in our pipeline and takes in GPS traces that have been filtered by all the other filters and snap them onto a road. This is data intensive and requires lot of DB querying but we have optimized it to run in tens of milliseconds. Following screenshot shows how we take raw GPS readings (red markers) and map them onto roads (blue markers).
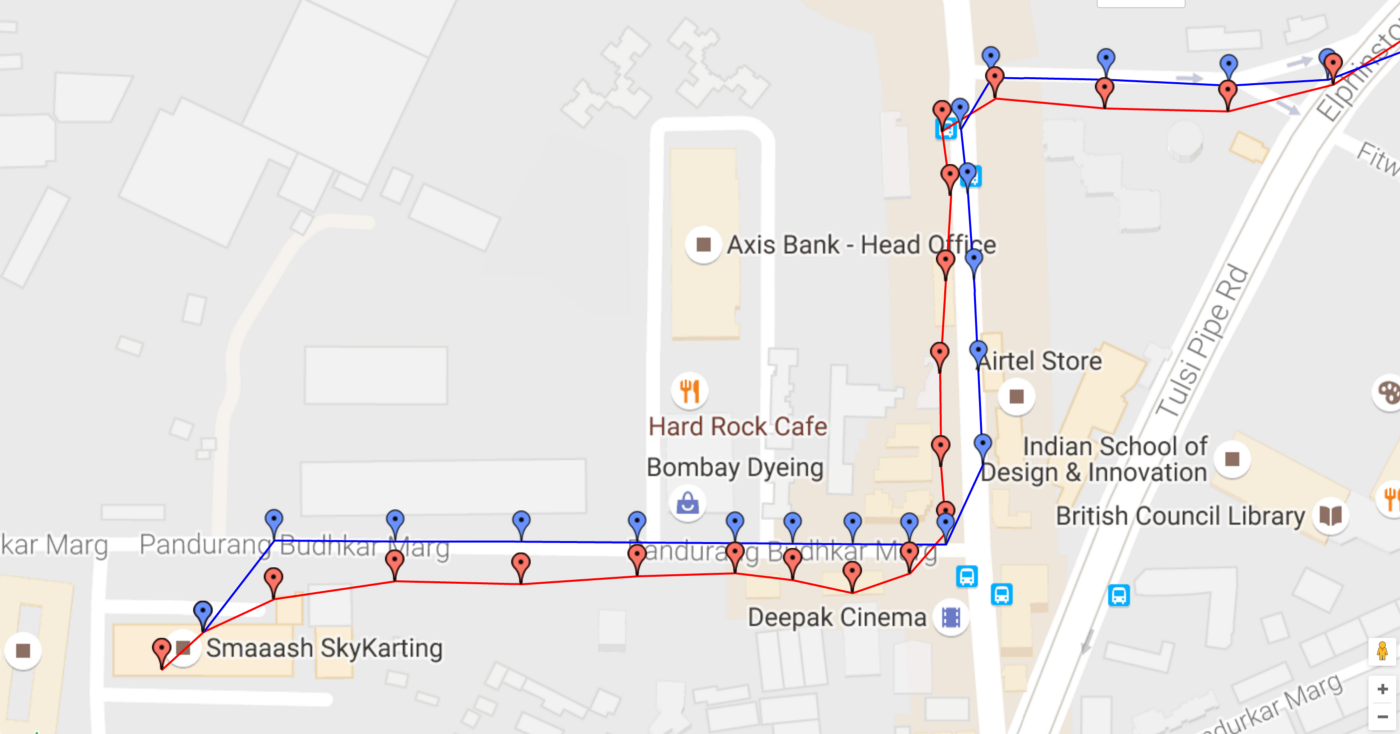
Let us look at some of our design constraints. At the time of writing this post, we have hundreds of users sending thousands of location readings through our SDK. It is imperative to process this incoming location stream quickly and efficiently so we can display near real-time status of these users. Every non-essential task (including filtering) needs to be performed asynchronously to have minimum turn around time in order to conserve battery on the user’s phone. We support offline mode where users need to continue operating their apps through patchy or no network areas for extended periods of time. When the network is back up, their accumulated locations are sent to the server in parallel batch calls. Hence the server can’t rely on receiving messages in the order they were recorded and should be able to process out of order location streams.
To satisfy these constraints, we needed an in-memory datastore which can maintain ordering of messages. We chose a combination of Redis SortedSet & Hashes to store hot data i.e. last X hours of GPS readings for every driver we are tracking. SortedSet supports ordering by timestamps and has an interface for retrieving keys before and after a given key (context is required for filtering). Hashes are great to store actual objects for quick lookups. Finally we are using Celery with CloudAMQP for asynchronous processing.
Everytime GPS readings are posted to the server, we write them to Redis and put a filtering task on Celery. The task gets picked up by a worker which builds the filtering context and runs through all the filters in our pipeline. Ultimately the result is updated in Redis and our persistent store PostgresDB. We care about performance and have optimized this workflow to run in hundreds of milliseconds end-to-end.
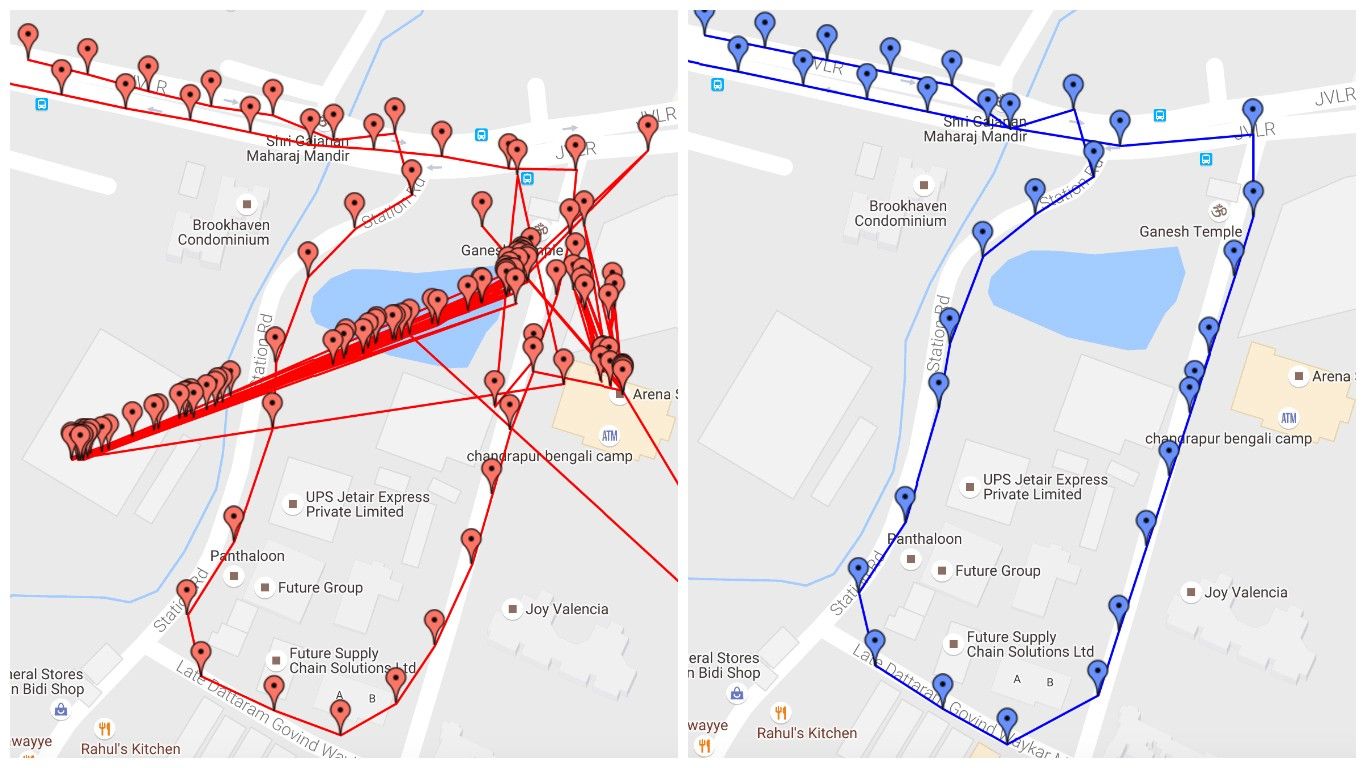
Look at the example below where a user’s device is sending us noisy location readings (on the left) and how we filtered it (on the right) to make sense out of his trip.
We have also built a validation framework to benchmark effectiveness of our filters. We chose a test-suite of ~10k trips and compared how far our filtered points are from where they ideally should be. Keeping this as a benchmark, we always run the suite before deploying a substantial change and only go ahead when the results are trending in a positive direction. We also use the test-suite to fine tune the configs on existing filters or tweak our algorithms. It helps us iterate rapidly in that we can build a new filter tweak it measure the impact and make deploy/discard decision in a short amount of time. We recommend this data oriented approach while optimizing for a fuzzy problem.
We are having fun building the location tracking platform. Hope you will enjoy using it as well. Sign up with HyperTrack to build movement-aware applications. And stay tuned to learn more about what is happening under the hood!

