

On-demand delivery networks connect a three sided marketplace made of merchants, customers and delivery riders. Performance of an on-demand delivery is measured as delivery time–time taken from placing the order to delivery to the customer.
Reducing delivery time leads to happier customers, higher income for delivery riders, and better business for the on-demand delivery company. The process to reduce delivery time begins with quantifying how time was spent on past deliveries, then forecasting how time will be spent on future deliveries, and then optimizing delivery time with actionables.
Stages of an on-demand delivery
A typical on-demand delivery starts with dispatch followed by pick-up and drop-off. The dispatch process ends with the order getting assigned to a delivery rider. The rider picks up the order from the merchant and then delivers it to the customer.
What leading on-demand companies do today
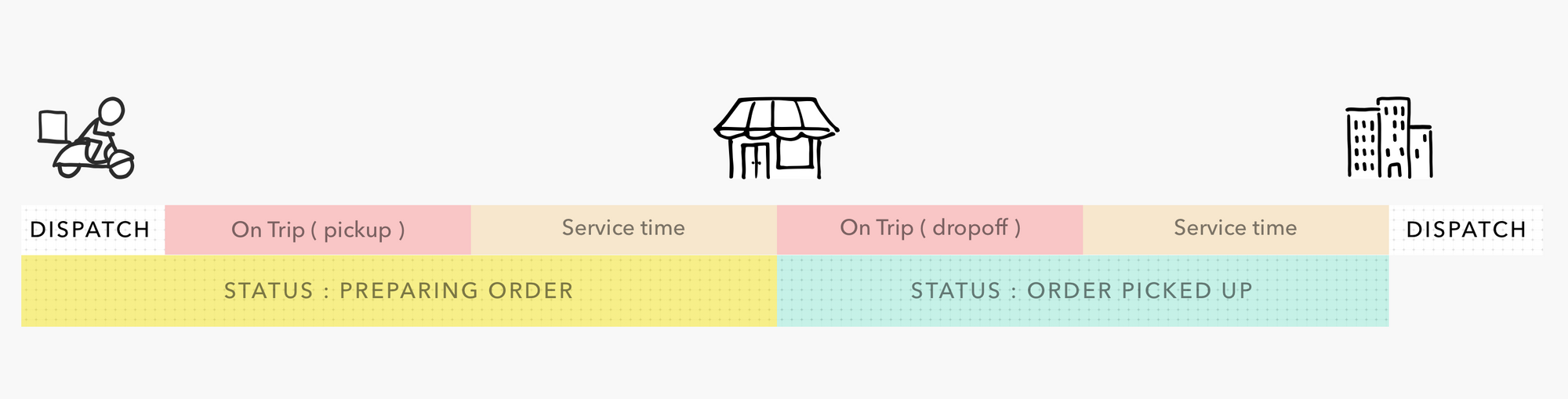
We spoke with leading on-demand businesses with delivery networks in US, UK and India. We learnt that teams are using location time series data from their rider apps to get insights about their delivery time. Data teams are able to break down the data for a typical on-demand delivery into five stages.
- Dispatch: Orders are assigned to available riders near the pick-up location. Data from past orders helps forecast and reduce dispatch times for future trips.
- On Trip (pick-up): Data teams use location data with map APIs and run pattern recognition techniques to break the time from dispatch to pick-up into trip time and service time.
- Service time: It is the time spent waiting and finishing pick up at the location. Once broken down, service times from past orders are used to identify anomalies.
- On Trip (drop-off): Similar to pick-up stages, time from pick-up to drop-off is broken into trip time and service time.
- Service time: Similar to pick-ups, service times from past orders are used to identify anomalies.
A handful of on-demand businesses with dedicated data teams have invested in inference of delivery stages. It takes substantial effort to achieve reasonable accuracy with location time series data.
Activity recognition offers significant improvement
Recent upgrades to hardware and Operating Systems have enabled Activity Recognition (AR) in devices running iOS and Android. Both OSes support detection of “driving”, “cycling”, “walking”, “still” and “unknown” as activity change events. Activity data can be used to increase the granularity of delivery stages and draw valuable insights from it.

Activity data can be used to accurately identify stages that tell a richer story. Pick-up and drop-off may each be broken into the following stages now: On Trip => Walk => Service Time => Walk back.
Additional insights due to activity
Variance in time taken to complete any of the stages increases uncertainty in delivery time. Measuring uncertainty in time taken to finish pick-up can be achieved by using activity data from past orders.
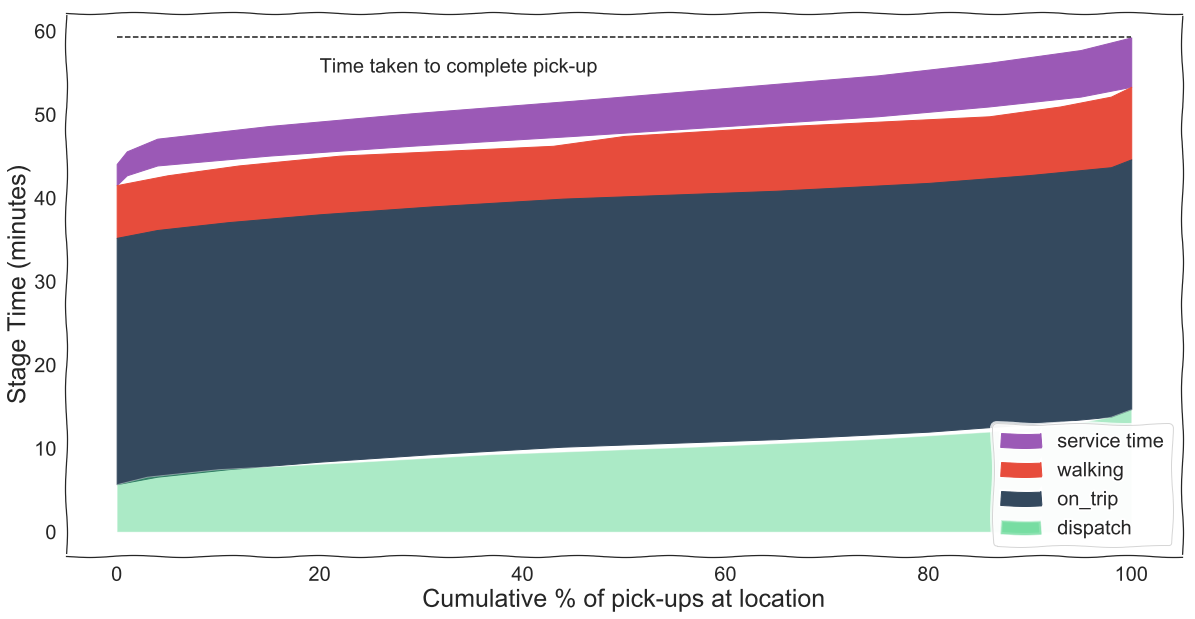
The distribution of dispatch times in the pick-up locality, on-trip time to the pick-up address, walking and service times for pick-up location stacked on top of each other, add up to the uncertainty in pick-up time for the location. We can now analyze each stage to figure out what we can do to reduce delivery time.
On Trip
The On Trip stage starts when the order is assigned and ends when the delivery rider app sends an activity change message confirming the drive end near the address. YumKenya, our partner in Nairobi, Kenya uses HyperTrack to get movement data for their food deliveries.
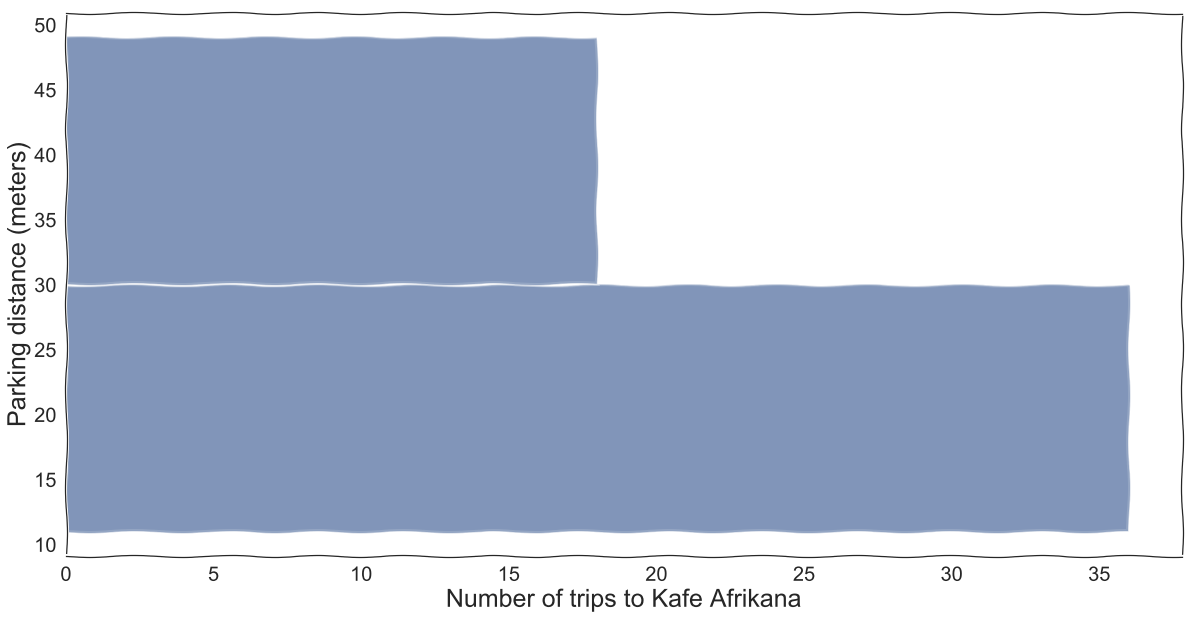
Using activity data from their past trips, they can calculate distances at which their delivery riders are parking at the end of the trip, for restaurants like the popular Kafe Afrikana restaurant. Parking spots are often available in areas at different distances from the pick-up location. By looking at past trips, drivers can be made aware of popular parking locations closer to pick-up. This will reduce delivery time by minimizing walking time.
Walking
When looking at the walking time data from parking locations to restaurants, we see that the walking time to the location is more often longer than the walking time back to the parking spot.
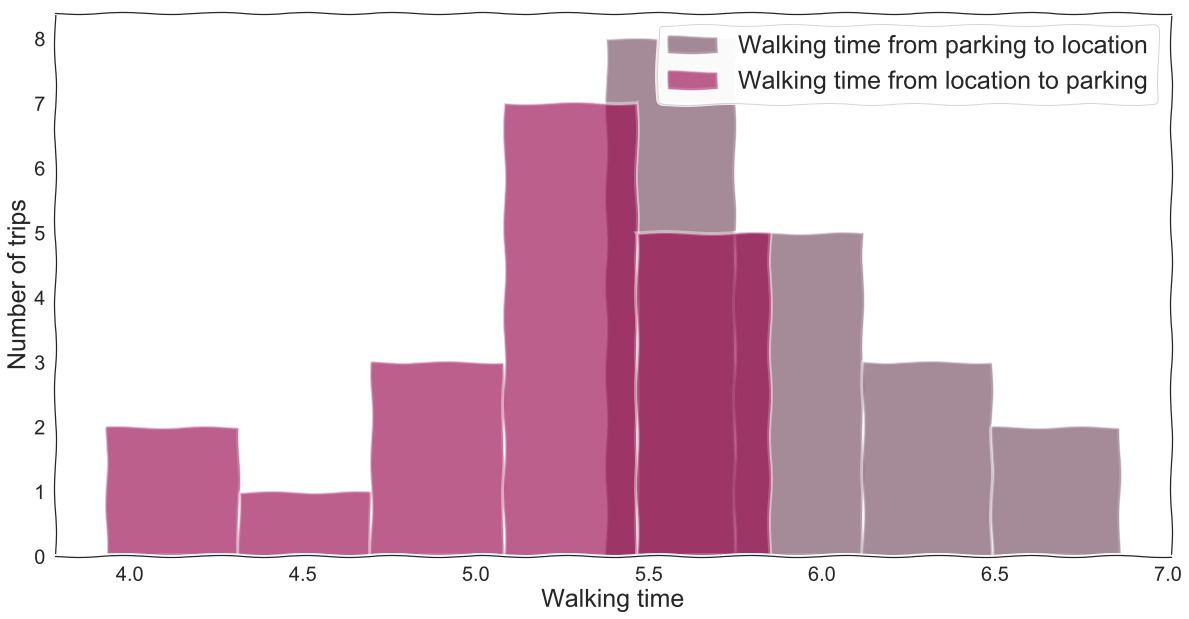
This characteristic of food delivery pick-ups for restaurants in Nairobi, Kenya may generalize to other cities. This insight suggests that walking directions to help riders navigate to the restaurant can reduce time spent in walking to the restaurant.
Service Time
Delivery riders often have to spend varying amount of times at the pick-up locations. This can happen due to early dispatch, longer than expected order preparation time or busy time window at the pick-up location.
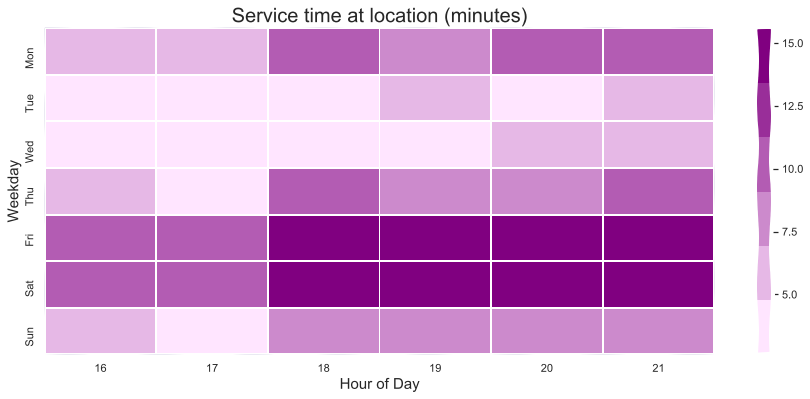
In absence of activity data, walking time adds noise to the service time measurement for a pick-up. Busy time windows at restaurants are often independent of parking distance and availability in the area. Segmenting the data with higher accuracy improves understanding of anomalies in service time. This significantly improves accuracy of ETA estimation for the pick-up and therefore the overall order delivery. Better estimations mean lower error rates, better expectations set for customers, faster deliveries, and better efficiency of the delivery network.
Upgrading the location data infrastructure
Quantifying the variance in time taken for each stage in a delivery is valuable for data teams focused on building better algorithms for their delivery networks. The challenge is now for teams to upgrade their location stack and take advantage of activity data. It is a challenge to do this without breaking existing data models and upstream applications like notification systems and dashboards.
A legacy location stack begins with data pipelines ingesting GPS data from devices, followed by map matching and merger with application events. Key components are:
- Streaming to ingest device data into cloud servers with real time data streams
- Data infrastructure to process the data for accuracy and readiness to merge with application workflows
- Monitoring dashboards and notification workflows to power a better experience within the team and keep stakeholders informed
- Machine learning models to make day-to-day workforce operations more efficient using data
Data wrangling of location data needs domain expertise to transform low level features into discrete interpretable values for upstream applications. For example, converting location time series data into trips and visits. A robust data infrastructure needs software engineering time and investment. Building and operating location data infrastructure for on-demand businesses comes at a high cost of expertise and infrastructure.
Zero infrastructure with activity data
HyperTrack works with leading on-demand businesses in the world to generate, process and manage delivery riders' movement data for their data teams to consume. Movement data merges location with activity data using the latest and greatest that the device, OS, real-time systems and cloud infrastructure providers have on offer. This way teams can focus on core applications that are important for business and leave it to HyperTrack to build and operate movement data infrastructure.

HyperTrack generates movement data in the Placeline format and makes it available as a stream of events, data pull or visual dashboard. Data teams can consume this data directly into their data models in near real-time.
This post focused on breaking an on-demand delivery into granular stages using activity and proposed three actionable ways to reduce delivery time. In the future, I will share a post that deals with scheduled deliveries (a.k.a. milk-runs). Please write to me with your use case and I would be happy to compare notes about ideas to use movement data.
I hope you found this post useful. If you have any follow-up questions or clarifications, please do not hesitate to ask. Please share your learnings and techniques in similar areas so we can share it with the HyperTrack user community.
To start generating movement data for your workforce, sign up for HyperTrack and get started in minutes!

